研究平台 | “吾与点”古籍智能整理平台
2021年5月28日
中华文明历史悠久,古典文籍浩如烟海。古籍具有极高的文献价值和学术价值,古籍整理不仅是连接现代和历史的桥梁,而且有利于民族文化的传承和研究。而古人在著书时一般不使用标点,现存的许多古籍也没有断句和标点,这给读者阅读学习和学者研究古籍造成了障碍。命名实体识别在古籍文献数字化处理过程中极为重要,是文白翻译、关系抽取等一系列自动化处理工作的基础,能够从古籍文献中自动识别出专名信息是一项非常重要且有价值的工作。传统的古籍整理通过选定某一代表性版本作为底本,通过与其他版本的对勘校订底本文字,同时施以现代标点,标示书名、人名、地名、朝代名,旨在提供一个文字准确,标点可靠,方便阅读的排印文本。“吾与点古籍智能整理平台第二版”是由北京大学数字人文研究中心研发的智能化古籍整理平台。“吾与点”平台将提供自动句读、分词、命名实体识别、关系抽取等基本古籍整理功能。目前提供公开测试的有自动句读、分词以及命名实体识别功能,其他功能将会陆续开放测试。
# 平台功能介绍
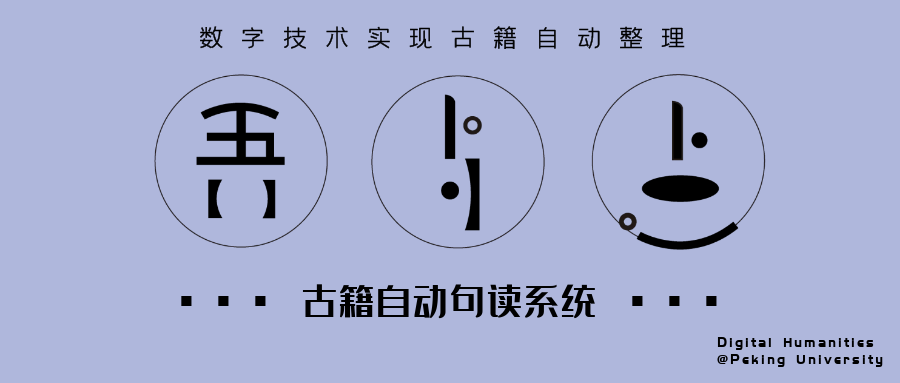
# 1. 句读及标点
未经整理的古代典籍不含任何标点,不符合当代人的阅读习惯,古籍断句标点之后有助于阅读、研究和出版。吾与点自动句读系统是基于深度学习的预训练语言模型 BERT 实现的,为了使模型能够具有更好的古汉语表示能力,我们利用 10 亿字的古汉语语料对 BERT 进行增量训练,在其基础上在进行句读学习。句读功能利用互联网上公开的古籍文本库训练得到,训练集包括 7 亿字。目前系统能够处理各类古籍文本,包括经史子集以及佛藏,道藏,通俗小说等。无论是先秦典籍还是明清小说,目前模型在混合类文本测试集上的句读平均准确率超过 94%,标点准确率达 90%,达到了实用标准。“吾与点”自动句读系统具有极高的处理速率和响应速率,经测试 API 接口处理 5 万字耗时 10 秒左右。
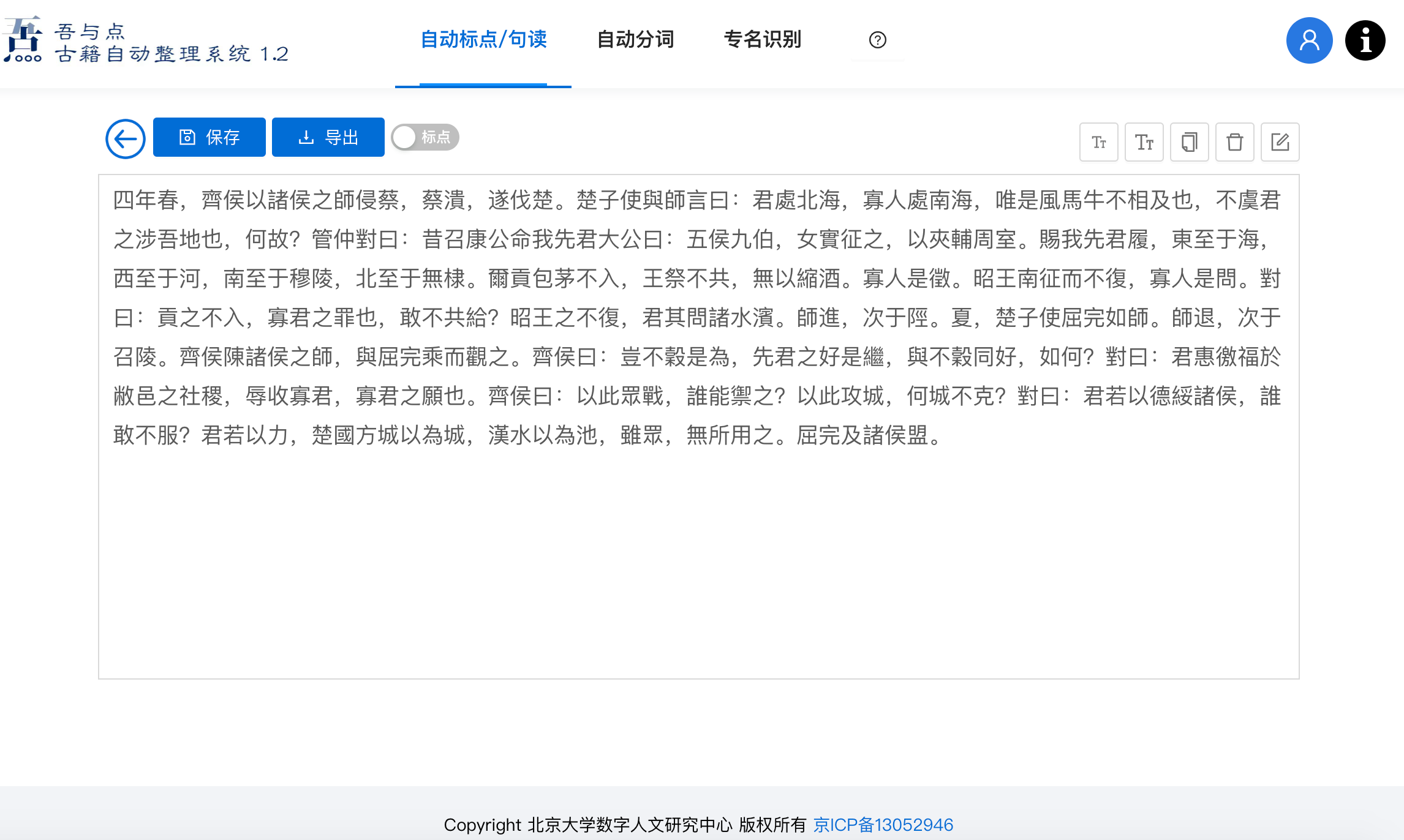
# 2. 分词
语言演化遵循渐变的规律,随着时间的推移,语法、词汇和语义逐渐发生了变化,导致了历时的语言鸿沟。然而,许多的文本中经常掺杂着不同时代的语言,这给自然语言处理任务带来了障碍,如分词和机器翻译等。“吾与点”自动分词模型在汉语分词任务中引入跨时代学习的研究,使得单一模型可以根据不同的时代的句子产生不同的分词粒度,具备跨时代分词能力。“吾与点”自动分词模型可实现对上古、中古、近古以及现代汉语文本的分词,在四个时代的分词平均 F1 值达到 98%。
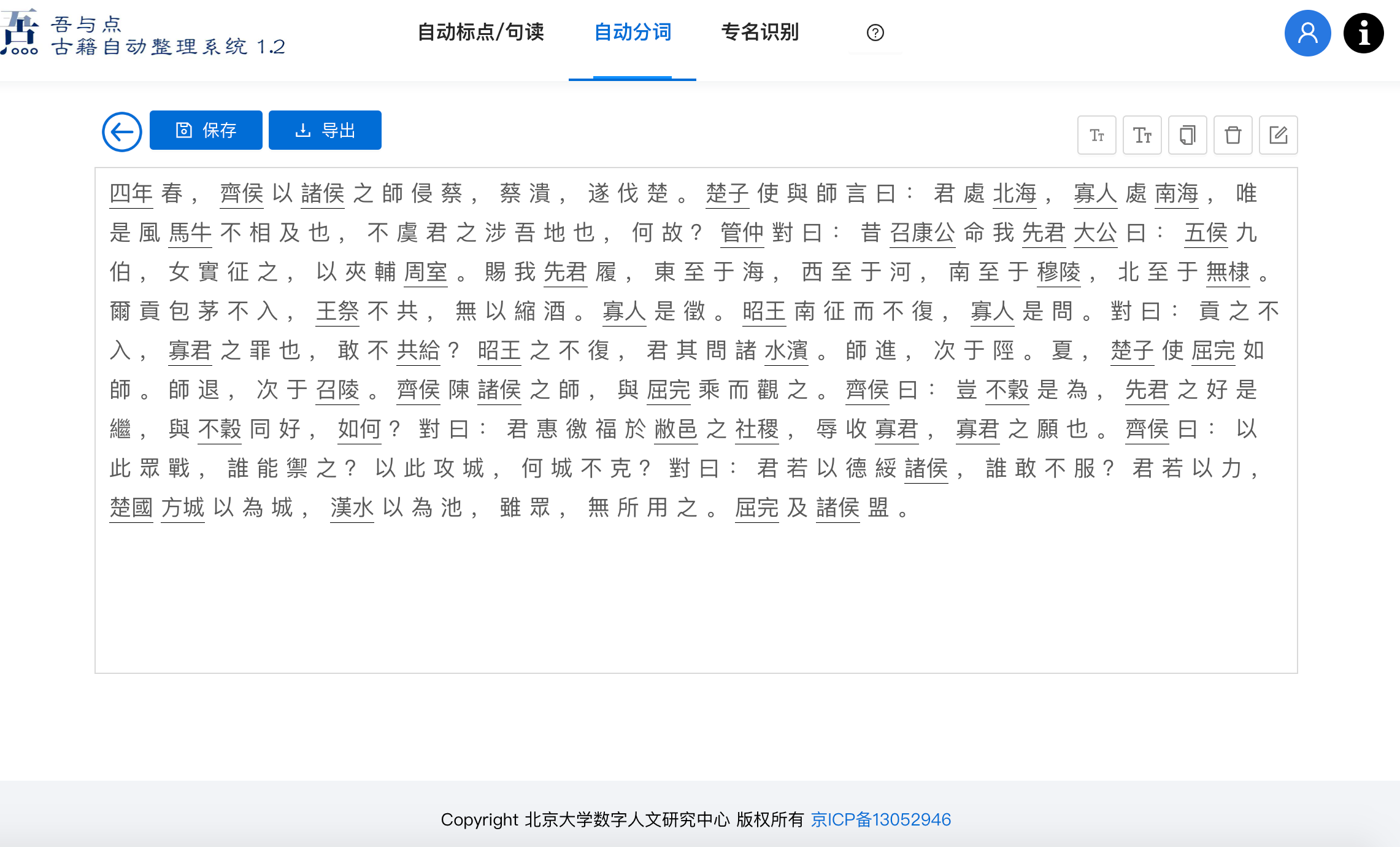
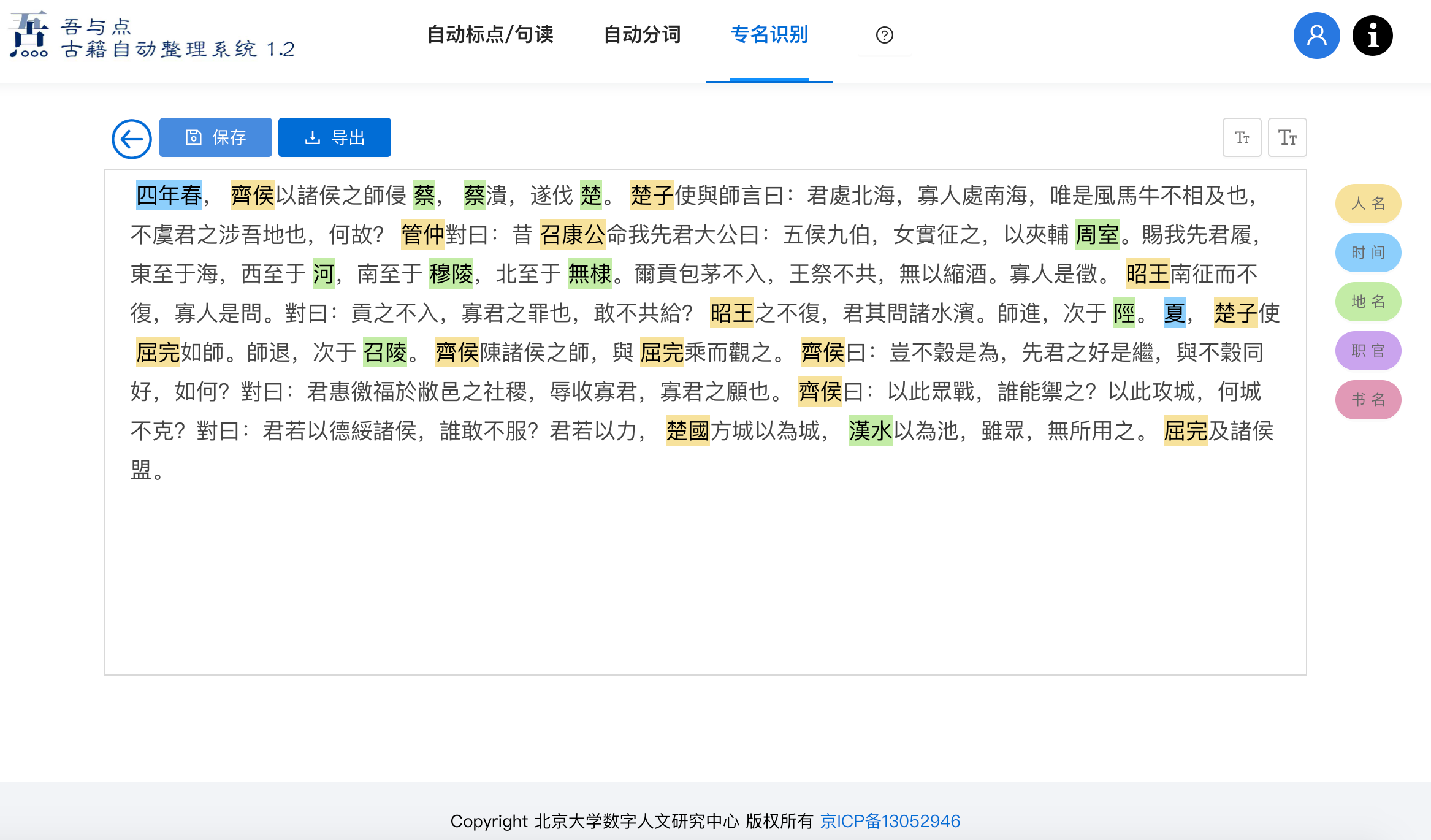
# 3. 命名实体识别
命名实体自动识别系统功能旨在从非结构化的输入文本中识别出各类专有名词。在实际的应用场景中,可以按照不同的业务需求识别出特定的实体,比如在古代历史文献中要识别地理、年号、职官、著书等常规命名实体。“吾与点”在以上提到的增量训练的 BERT 模型基础上,应用迁移学习实现古籍命名实体识别。经测试,现有模型在与训练语料同类型的测试语料上,其准确率达到 98.5%。在《尚书》、《春秋》等先秦上古语料上对人名、地名的泛化准确率分别达到 87%和 82%,在明清小说上测试识别准确率达到 80%。上述的准确率水平,表明当前基于预训练模型的深度学习方法在中华古籍文本上的句读和专有名词识别已经取得与专业人员相媲美的表现,准确率的进一步提升完全取决于标记语料的质量和覆盖率。
# 团队成员
- 指导教师:王军、苏祺、杨浩
- 模型研发:唐雪梅、严承希
- 数据处理:唐雪梅、陈雨航
- 前端开发:付炳豪、黄恒博
- 后端开发:付炳豪、孟令勇
- Logo 设计:李若屹
- 界面设计:梁利敏、汪博涵、李文琦
# 访问地址
http://wyd.pkudh.xyz/ (opens new window)
# 联系和反馈
在试用系统时遇到的各类问题,欢迎您及时地反馈给我们。您反馈的问题将有助于我们进一步完善系统,为您提供更好的服务。联系方式:gdhc@pku.edu.cn